 English
English
Documentation Utilisateur XSM
Note: Cette documentation s'applique à la dernière version XSM. Pour les versions précédentes, lancez XSM sans paramètre pour afficher l'aide et la liste des options supportées par la version.Sommaire
- Introduction à XSM
- Installation de XSM
- Lancement de XSM
- Paramètres
- Syntaxe de la ligne de commande
- Exemples de tris : La meilleure façon de commencer !
- Job 1 : Un fichier texte
- Job 2 : Un fichier texte, redirection du flux stdout
- Job 3 : Un fichier texte, redirection des flux stdin,stdout
- Job 4 : Deux fichiers binaires, sortworks sur disques différents pour optimiser les I/O
- Job 5 : Deux fichiers binaires, filtrage des enregistrements par OMIT
- Job 6 : Un fichier texte type CSV à champs de longueur variable avec séparateur de champs
Regardez notre Démo illustrée - Job 7 : Un fichier binaire contenant des zones "Packed Decimal"
- Job 8 : Un fichier texte avec des champs dates au format 'mmjjaa', changement du pivot de siècle Y2K
- Job 9 : Plusieurs fichiers texte avec identification et élimination des doublons
- Job 10 : Copie d'un fichier avec éclatement sélectif sur plusieurs fichiers
- Job 11 : Tri d'un fichier avec éclatement sélectif sur plusieurs fichiers
- Job 12 : Tri/Fusion de fichiers et éclatement sélectif sur plusieurs fichiers
- Job 13 : "Tout en Un" : Fusion + Dédoublonnage + Skip Header + sortie sélective CSV
- Job 14 : Portage d'un step de JCL MVS avec XSM
- Tri Destructif et non destructifs
- Conseils pour les performances
- Utilisation de la librairie de programmation XSM (User Exit)
- Messages & Codes retour
- CHANGELOG
- FAQ
1. Introduction à XSM
XSM est un programme de tri, qui lit un ou plusieurs fichiers en entrée, trie toutes les lignes ou enregistrements d'après des critères, ou 'clés' de tri, définis par l'utilisateur, et écrit le résultat final sur un fichier de sortie, en applicant des filtres 'Inclure/Exclure' éventuels.
XSM peut trier 2 types de fichiers :
- Les fichiers à enregistrements de longueur fixe (RECFM=F), ou fichiers 'binaires' :
Toutes les lignes ou 'enregistrements' sont de même longueur, y compris le caractère de fin de ligne Carriage Return/Line Feed (DOS, Windows ...), ou Line Feed (UNIX), s'ils existent (CR et LF sont traités comme les autres caractères). -
Les fichiers texte à longueur variable, également nommés "fichiers plats" :
Chaque ligne est délimitée par un CR/LF (DOS, Windows, ...), ou un simple LF (UNIX).
Les critères de tri peuvent se trouver à des emplacements fixes (FIELDS), ou des champs de longueur variable, séparés par un caractère séparateur (FIELDSEP).
Le "parmfile" est principalement utilisé pour les paramètres statiques, tels que clés de tri, sortworks, et options.
Vous pouvez également spécifier les paramètres sur la ligne de commande, au lieu d'utiliser un "parmfile". Ceci est décrit ci-dessous à la section syntaxe de ligne de commande.
Ceci est principalement utilisé pour passer les paramètres variables, tels que noms de fichiers en entrée/sortie. Vous pouvez ainsi tirer partie des variables d'environnement dans des scripts batchs (shell UNIX, Windows .bat) pour passer à XSM les noms de fichiers en entrée/sortie.
Il est recommandé d'utiliser le parmfile associé à la ligne de commande :
- le parmfile contient toutes les définitions statiques, tels que clés de tris, les options de filtrage
*************** parameter file job1.xsm ********* SORT FIELDS=(14,7,C,A) ; une clé de tri : position 14, sur longueur 7, Charactères, Ascending RECORD RECFM=V,LRECL=200 ; format texte variable avec CR/LF, longueur max 200 car OMIT DUPKEYS ; raccourci de OMIT DUPLICATE KEYS : dédoublonne
- la ligne de commande contient les variables dynamiques, telles que noms de fichiers en entrée/sortie.
hxsm690 --verbose --inpfile=/data/fp1.dat --outfile=/data/fp1.sorted job1.xsm
Au lancement, XSM calcule automatiquement les meilleures valeurs de ressources mémoire et fichiers disques temporaires ("sortworks") à utiliser en fonction de la nature et taille des fichiers en entrée. Ainsi, dans la plupart des cas, aucun tuning n'est nécessaire à XSM.
XSM fonctionne par défaut en mode dit "destructif" pour privilégier les performance, à l'opposé du mode dit "non-destructif" ou "stable".
L'option KEEP_ORDER le rend non-destructif ou "stable".
Cf. explications "tri destructif/non-destructif" ci-dessous.

2. Installation de XSM
L'installation du programme XSM est simple et prend quelques minutes.
XSM consiste en un programme exécutable 'hxsm', accompagné d'un utilitaire d'activation de licence 'hhnsinst' à exécuter une fois lors de l'installation.
Aucun pré-requis Matériel/Logiciel n'est nécessaire à XSM pour fonctionner sur votre Système d'Exploitation.
Consultez simplement le guide d'installation UNIX/Linux ou Windows.
Une fois le programme exécutable XSM activé, vous pouvez le renommer / le déplacer comme bon vous semble sur votre système.
Notez que l'exécutable XSM se nomme 'hxsm' pour éviter toute confusion avec le programme UNIX X11 Session Manager 'xsm'.
Tips :
-
Il est conseillé de renommer le programme XSM avec nom banalisé, pour faciliter les mises à jours de releases XSM sans avoir besoin de modifier les scripts batchs. Autrement dit, ôter toute référence de version XSM des scripts batchs.
Sous UNIX, utiliser les liens symboliques :$ cd /usr/local/bin $ # On utilise XSM version 6.71: $ ln -s hxsm671_Linux2.6.9-1.667_i686_32 hxsm $ ls -l hxsm* lrwxrwxrwx 1 root root 7 Apr 28 11:28 hxsm -> hxsm671_Linux2.6.9-1.667_i686_32 -rwxrwxr-x 1 root root 109160 Feb 19 2005 hxsm662_Linux2.6.9-1.667_i686_32 -rwxr-xr-x 1 root root 107744 Oct 31 2007 hxsm668_Linux2.6.9-1.667_i686_32 -rwxr-xr-x 1 root root 107744 Oct 28 2008 hxsm669_Linux2.6.9-1.667_i686_32 -rwxr-xr-x 1 root root 100480 Feb 8 2010 hxsm671_Linux2.6.9-1.667_i686_32
- Il est conseillé d'ajuster la variable PATH (UNIX/Windows) pour que l'appel XSM ne nécessite pas de spécifier le chemin complet du programme :
- soit en copiant le programme
hxsmdans un répertoire d'utilitaires déjà dans le PATH :
par exemple/usr/local/binpour UNIX/Linux,D:\applicationspour Windows - soit en ajoutant en tête de scripts (Shell UNIX, Windows .bat) le PATH sur le répertoire d'installation de XSM :
PATH=/apps/xsm:$PATH export PATH hxsm -v myparmfile.xsm
- soit en copiant le programme
Un programme exécutable XSM est lié au Système d'Exploitation sur lequel il a été activé. Ainsi, si vous copiez l'exécutable sur un autre système semblable, il est nécessaire d'activer XSM sur le système cible.
3. Lancement de XSM
Le lancement de XSM est très simple :
1) Créez un fichier paramètres décrivant le travail à faire :
- quel(s) fichier(s) trier (à défaut de standard input)
- quel type de fichiers : Fixes ou Variables
- quels critères (ou "clés") de tri
- où écrire le résultat final (à défaut de standard output)
- quelles ressources utiliser : mémoires, espace disque ...
- les options éventuelles (filtre, dédoublonnage, ...)
2) A l'invite (Terminal UNIX ou fenêtre invite Windows cmd.exe) du système, entrez :
hxsm votre-parmfile
3) Option -v 'Verbose':
On peut suivre le déroulement du tri, avec la durée de chaque phase avec le l'option -v (verbose) ou -vv (very verbose):
hxsm -vv votre-parmfile
4) Option -c 'Check' :
Pour contrôler, une fois le tri terminé, que le fichier en sortie est correctement trié selon les critères du fichier de paramètres:
hxsm -v -c votre-parmfile
A noter que l'on peut spécifier la plupart des paramêtres sous forme d'options traditionnelles sur la ligne de commande, sans utiliser de parmfile. Cela est utile pour passer les noms de fichiers en entrée/sortie provenant de variables d'environnement.
La section suivante décrit les paramètres du parmfile.
Pour une prise en main rapide, consultez les Exemples de tris ci-dessous.
Pour afficher l'aide, lancez
hxsm ou hxsm -h ou hxsm --help
4. Paramètres
XSM lit ses paramètres depuis un simple fichier texte. Nous l'appelons "Fichier Paramètres" ou "parmfile".Si vous préférez ne pas utiliser de parmfile, dans la plupart des cas les paramètres peuvent être spécifiés sur la ligne de commande.
Le fichier paramètres est une suite de lignes de paramètres du type :
SORT/MERGE - obligatoire si pas d'OPTION COPY
RECORD - obligatoire
INPFIL - optionnel
OUTFIL - optionnel
OUTREC - optionnel
INCLUDE - optionnel
EXCLUDE|OMIT - optionnel
OUTFILDUP - optionnel
SORTWORKS - optionnel
IOERROR - optionnel
STORAGE - optionnel
OPTION - optionnel
Les instructions peuvent commencer en n'importe quelle colonne, mais il est conseiller de commencer en colonnes 1 à 8 pour la lisibilité.
Les marques de commentaires sont :
- un point-virgule
(;)en n'importe quelle colonne de la ligne,
- ou un Astérisque
(*)en début de ligne,
- ou un Dièse
'#'en début de ligne.
# ceci est un commentaire * ceci est un commentaire ; ceci est un commentaire INPFIL /tmp/data/myinput.file ; ceci est un commentaire pour le fichier en entrée
Les lignes de commentaires ainsi que les vides sont permises n'importe où dans le fichier de paramètres.
Le paramètre SORT/MERGE
SORT ou MERGE FIELDS=(pos,long,type,direction[,pos,long,type,direction,..])
ou
FIELDS=(pos,long,direction[,pos,long,direction,..]),FORMAT=type
ou
FIELDS=ALL
ou
VFIELDS=(pos,long,type,dir.[,pos,long,type,dir.,..]),FIELDSEP=car
pos : position de début d'une clé de tri (pour FIELDS=)
rang de la clé de tri (pour VFIELDS=)
long : longueur de cette clé (pour FIELDS=)
longueur maximum de cette clé (pour VFIELDS=)
type : B ou BI (Binary) - champ binaire
C ou CH (Char) - en caractères classique ascii (par défaut)
I (Ignore Case) - champ alphanumérique,
ne pas différencier minuscules/Majuscules
N ou NU (Numeric) - champ considéré comme numérique :
caractères '0'..'9' (VFIELDS seulement)
P ou PD (Packed) - Décimal Packé
(Binary files only, last half Byte = sign)
Y ou Y2K - champ numérique de 2 octets contenant le millésime (les dizaines)
d'une date (AA) : contient '84' pour l'année 1984. L'année de
pivot (option Y2KSTART, 1970 par défaut) sert à déterminer
si une année, par exemple 17, signifie 1917 ou 2017. (cf Y2K faq)
direction : A (Ascending order), D (Descending order)
FORMAT : forme simplifiée utilisée seulement lorsque toutes les clés de tri ont le même type
Ainsi on peut simplifier
SORT FIELDS=(14,10,CH,A,24,10,CH,A)
en :
SORT FIELDS=(14,10,A,24,10,A),FORMAT=CH
FIELDSEP : Le délimiteur/séparateur de champs FIELDSEP peut être un nom symbolique, un simple
caractère, ou une valeur hexadécimale.
L'utilisation de noms symbolique est recommandée pour la ponctuation générale, pour
éviter des erreurs d'analyse de syntaxes, spécialement avec des séparateurs ';', '#'.
Noms Symboliques acceptés :
BAR = the '|' char
TAB = the Tabulation (X'09') char
COMMA = the ',' char
COLUMN = the ':' char
DIARESIS = the '#' char
SLASH = the '/' char
BACKSLASH = the '\' char
SEMICOLUMN or SEMI-COLUMN = the ';' char
SINGLEQUOTE or SINGLE-QUOTE = the "'" char
DOUBLEQUOTE or DOUBLE-QUOTE = the '"' char
Valeur Hexadécimale : X'hh'
(Hex syntax : UPPERCASE X, Singlequote, 2 Hex digits,Singlequote)
La valeur par défaut est la Tabulation
Exemples :
VFIELDS=(.....),FIELDSEP=SEMI-COLUMN
VFIELDS=(.....),FIELDSEP=@
VFIELDS=(.....),FIELDSEP= ; FIELDSEP est l'espace ou "blanc"
VFIELDS=(.....),FIELDSEP=X'7C'
VFIELDS=(.....) ; FIELDSEP=TAB par défaut
Paramètre équivalent ligne de commande : --sort / --merge --key=
On utilise le verbe SORT pour trier un ou plusieurs fichiers.
On utilise le verbe MERGE pour fusionner au moins deux fichiers déjà triés.
Pour bien comprendre la différence entre SORT et MERGE, consultez la discussion SORT/MERGE.
L'un ou l'autre des paramètres SORT ou MERGE est obligatoire, sauf si l'OPTION COPY est utilisée.
Le paramètre FIELDS= décrit les champs (ou clés) de tri à des position fixes sur la ligne (RECFM=V) ou l'enregistrement (RECFM=F).
FIELDS=ALL indique que la clé de tri est la ligne entière ou l'enregistrement entier.
Le paramètre VFIELDS décrit les clés de tri à longueur variable séparées par un caractère donné.
Ce paramètre ne peut pas être utilisé pour les fichiers binaires (RECFM=F).
Avec le paramètre VFIELDS, on spécifie le séparateur de champs avec FIELDSEP= (cf. ci-dessus).
SORT FIELDS=(17,3,B,D,1,15,B,A)
ou
SORT FIELDS=(17,3,BI,D,1,15,BI,A)
ou
SORT FIELDS=(17,3,D,1,15,A),FORMAT=BI
Ils signifient :
- la 1ère clé commence en colonne 17 de chaque enregistrement, sur une longueur de 3, donc se termine en colonne 17 + 3 - 1 = 19, type Binaire, tri Descendant,
- la 2nde clé commence en colonne 1, sur une longueur de 15, donc se termine en colonne 1 +1 5 - 1 = 15, type Binaire, tri ascendant.
SORT FIELDS=(2,4,B,A) ; trie un long (4x8=32 bits) en ordre Descendant (fichier créé sur OS 32-bits) SORT FIELDS=(6,2,B,D) ; trie un short (16 bits) en ordre Ascendant (fichier créé sur OS 32-bits) SORT FIELDS=(2,8,B,A) ; trie un long (8x8=64 bits) en ordre Descendant (fichier créé sur OS 64-bits)
Tri d'un fichier texte sur un nom de colonne 12 à 31 (12 + 20 - 1 = 31), ignorer la 'casse' :
SORT FIELDS=(12,20,I,A)
Tri d'un fichier binaire sur un nombre 'Packed Decimal', col. 7-10, ordre inverse :
SORT FIELDS=(7,4,P,D) ; 7 BCD digits, signé
Tri d'un fichier de texte, champs variables, séparateur ':'
- un nom dans le champ 12, longueur maxi 20 caractères, ignorer la 'casse';
- un nombre dans le champ 7, au plus 9 chiffres (car. '0' .. '9'), ordre inverse
SORT VFIELDS=(12,20,I,A,7,9,N,D),FIELDSEP=:
Idem avec un espace en guise de séparateur :
SORT VFIELDS=(12,20,I,A,7,9,N,D),FIELDSEP=
Idem avec une tabulation en guise de séparateur :
SORT VFIELDS=(12,20,I,A,7,9,N,D),FIELDSEP=TAB
ou
SORT VFIELDS=(12,20,I,A,7,9,N,D) ; FIELDSEP=TAB implied (défaut)
Tri d'un fichier de texte avec date de la forme 'mmjjaa', colonne 21-26, ordre décroissant
SORT FIELDS=(25,2,Y,D,21,2,B,D,23,2,B,D)
Tri d'un fichier de texte tel quel, sur toute la ligne :
SORT FIELDS=ALL
Voir des exemples de jobs XSM
Le paramètre RECORD
RECORD RECFM=record format,LRECL=record length
record format : F pour longueur fixe
V pour longueur variable
T pour du Texte (V et T sont équivalents)
M pour du MicroFocus "MFCOBOL"" ou "MFVariable"
record length : Longueur exacte d'enregistrement pour RECFM=F, y compris un évenutel séparateur CR/LF
Longueur max. d'enregistrement pour RECFM=V, sans compter le séparateur de ligne CR/LF
Paramètre équivalent ligne de commande : --recfm= --lrecl=
Le paramètre RECORD indique si le format d'enregistrement est fixe ou variable, et sa longueur.
Le paramètre RECORD est obligatoire.
Avec RECFM=V, LRECL est automatiquement incrémenté de 2 pour inclure CR/LF (fichiers plats Windows/UNIX)
RECFM=M est utilisé pour le format spécial Microfocus Variable Format Record Sequential File
connu sous le nom "MFCOBOL" ou "MFVariable", composé :
- d'un header 128 octets
- d'une suite de records [ Header ][ Variable length data ][ Padding ].
- d'une suite de records [ 4 Bytes Record Descriptor Word (RDW) header ][ Variable length data ]
Pour trier des fichiers de format Variable IBM Mainframe reçus par FTP de DOS/VSE, MVS, z/VM, z/OS :
- Transfert FTP ASCII, Quote site NORDW (par défaut) :
Une fois transférés sous Unix/Windows, les fichiers sont en format texte ASCII, enregistrements de longueur variable avec CR/LF, sans le RDW.
Pour XSM, indiquer RECORD RECFM=V,LRECL=xxxx (xxxx = la longueur max des records) - Transfert FTP ASCII, Quote site RDW :
Une fois transférés sous Unix/Windows, les fichiers sont en fomat texte ASCII, enregistrements de longueur variable terminés par CR/LF, préfixés par le RDW (en binaire).
Pour XSM, indiquer RECORD RECFM=V,LRECL=xxxx (xxxx = la longueur max des records) et décaler (rajouter +4) toutes les positions des clés de tri. - Transfert FTP Binaire, sans RDW:
N'a pas de sens car on ne connait plus la longueur des enregistrements.
- Transfert FTP Binaire, avec RDW:
Non supporté par XSM.
Exemples :
RECORD RECFM=F,LRECL=400
signifie que tous les enregistrements sont de même taille (400 octets, y compris les CR/LF éventuels)
La taille du(des) fichier(s) en entrée est forcément un multiple de 400.
RECORD RECFM=V,LRECL=133
signifie qu'il s'agit d'un fichier de texte, dont les lignes font 133 caractères au maximum (sans compter CR/LF);
Voir des exemples de jobs XSM
Le paramètre INPFIL
Forme 1 :
INPFIL filename
filename : nom du fichier en entrée
Paramètre équivalent ligne de commande : --infile=
Forme 2 :
INPFIL DD:varname
varname : Variable d'environnement contenant le nom du fichier en entrée
Le paramètre INPFIL indique le nom des fichiers en entrée.
Le paramètre INPFIL est optionnel. Si absent, 'standard input' (stdin) est utilisé pour le fichier en entrée (les redirections et pipe UNIX sont permises).
Une ligne INPFIL par fichier en entrée
A partir des versions 4.50/5.10, les fichiers peuvent être spécifiés "à la MVS" par un DDname : DD:variable
Dans ce cas, XSM récupère le nom du fichier via la variable d'environnement correspondante.
INPFIL C:\Myjob\BIGF.INP # Windows INPFIL D:\TMP\Wrk.Dat # Windows INPFIL /home/hh/bigf.inp # UNIX INPFIL /home/hh/littlef.inp # UNIX INPFIL DD:SORTIN1 # any systems INPFIL DD:SORTIN2 # any systems INPFIL DD:JOHNNY # any systems # SORTIN1 SORTIN2 et JOHNNY sont les variables d'environnement contenant les noms de fichiers.
Voir des exemples de jobs XSM
Le paramètre OUTFIL
Le paramètre OUTFIL indique le nom des fichiers en sortie, et les filtres INCLUDE/EXCLUDE éventuels.Il permet ainsi de définir des filtres au niveau de chaque fichier en sortie.
Le paramètre OUTFIL est optionnel. Si absent, 'standard output' (stdout) est utilisé pour le fichier en sortie (les redirections et pipe UNIX sont permises).
Note: le fichier en sortie peut être le même que l'un des fichiers en entrée mais sur une opération SORT uniquement.
Forme 1 : le fichier en sortie indiqué "en dur" dans le fichier paramêtre
OUTFIL filename[,INCLUDE/EXCLUDE=(condition1,[AND/OR,condition2...)]
[,RECFM=recfm][,LRECL=lrecl][,DISP=disp]
filename : nom du fichier en sortie
condition : pos,long,datatype,operateur,pattern
pos : colonne de début de la zone à comparer
long : longueur de la zone à comparer
type : 'CH' (Char) ou 'BI' (Binary)
operateur : EQ ou NE ou LT ou LE ou GT ou GE
pattern : C'cccc' où cccc = chaîne de caractère à comparer
X'xxxx' où xxxx = valeur hexadécimale à comparer
N'nnnn' où nnnn = valeur numérique à comparer (à partir de la v6.92)
La longueur de la valeur doit être égale à la longueur de la zone à comparer
recfm : format d'enregistrement en sortie, s'il doit est différent de celui en entrée :
RECFM=V ou RECFM=F
lrecl : longueur d'enregistrement en sortie, si différente de celle en entrée.
Pour RECFM=V (variable), tronque l'enregistrement si plus petit que LRECL en entrée
Pour RECFM=F, tronque si plus petit que LRECL en entrée
fait un padding si plus grand que LRECL en entrée
disp : "Disposition" en cas d'existence du fichier en sortie avant lancement du tri :
DISP=NEW : s'arrête si le fichier en sortie existe déjà
DISP=OVERWRITE : écrase le fichier en sortie s'il existe déjà (défaut)
DISP=APPEND : écrit en "Append" si le fichier en sortie existe déjà
Paramètre équivalent ligne de commande : --outfile=
Forme 2 : le fichier en sortie décrit par une variable d'environnement
OUTFIL DD:varname[,INCLUDE/EXCLUDE=(condition1,[AND/OR,condition2...)]
[,RECFM=recfm][,LRECL=lrecl][,DISP=disp]
varname : Variable d'environnement contenant le nom du fichier en sortie
Forme 3 : association FILE=nn / variable SORTOFnn
Déprécié, maintenu pour compatibilité IBM DF/SORT et versions XSM antérieures. Utiliser la forme DD:varname à la place.
OUTFIL FILE=nn[,INCLUDE/EXCLUDE=(condition1,[AND/OR,condition2...)]
[,RECFM=recfm][,LRECL=lrecl][,DISP=disp]
FILEnn représente la variable d'environnement SORTOFn où nn est un nombre supérieur à 0.
Exemple :
OUTFIL FILE=01,INCLUDE=(8,2,CH,EQ,75) ; variable SORTOF1 pour le département Paris
OUTFIL FILE=02,INCLUDE=(8,2,CH,EQ,14) ; variable SORTOF2 pour le département Calvados
OUTFIL FILE=971,INCLUDE=(7,3,CH,EQ,971) ; variable SORTOF971 pour le département Guadeloupe
...
Exemples :
OUTFIL D:\TMP\BIGF.OUT ; Windows full pathname style, pas de filtres
OUTFIL /home/hh/bigf.out ; UNIX full path name style, pas de filtres
OUTFIL DD:FOO ; utilisation de variable FOO, pas de filtres
OUTFIL DD:FOO2,EXCLUDE=(11,3,CH,EQ,C'POP') ; retire en sortie tous les enregistrements
; qui contiennent 'POP' en colonne 11
OUTFIL /data1/clients1.dat,EXCLUDE=(11,3,CH,EQ,C'POP') ; idem, mais fichier codé en dur
; au lieu de variable
OUTFIL DD:XYZ1,INCLUDE=(11,3,CH,EQ,C'MAR',
OR,
11,3,CH,EQ,'GAS') ; ne sort que les enregistrements qui
; contiennent 'MAR' ou 'GAS' en colonne 11
Note : Ne pas insérer de commentaires à l'intérieur d'une clause conditionelle !
Cf. exemple de job avec COPY et sorties sélectives DD:...,INCLUDE=(...)
Les paramètres INCLUDE/EXCLUDE/OMIT
INCLUDE décrit les conditions pour conserver des enregistements.
EXCLUDE ou OMIT décrivent des conditions pour éliminer des enregistrements.
Forme 1 : Dédoublonnage, 1 ou plusieurs fichiers en sortie
NONE ; ne supprime rien (par défaut, pour compatibilité IBM DF/SORT)
DUPLICATE KEYS ; supprime toutes les lignes ou enregistrements avec la clé de tri
ou DUPKEYS ; en double ; équivalent du SUM FIELDS=NONE de DFSORT.
OMIT ou DUPKEY
DUPLICATE RECORDS ; supprime toutes les lignes ou enregistrements en double
ou DUPRECORDS
ou DUPRECORD
ou DUPRECS
ou DUPREC
Paramètre équivalent ligne de commande : --unique-key / --unique-record
Il est possible d'écrire tous les doublons (sur clé ou enregistrement) dans un fichier séparé,
avec le paramètre OUTFILDUP, et l'option WRITEFIRSTDUPLICATE.
Forme 2 : Filtrage conditionnel, 1 seul fichier en sortie
INCLUDE
EXCLUDE COND=(column,length,type,operator,pattern[,AND|OR,col,len,type,oper,pattern,...])
OMIT
col : début de zone à examiner dans chaque ligne (1..n)
len : longueur de la zone
type : CH (ignoré mais pour compatibilité IBM SORT...)
operateur : EQ ou NE ou LT ou LE ou GT ou GE
pattern : valeur de comparaison, de la forme C'ccccc...' où ccccc est une chaîne de caractères
X'xxxxx...' où xxxxx est une valeur hexadécimale
à partir de la v6.92 : N'nnnnn...' où nnnnn est une valeur numérique
à partir de la v6.93 : nnnnn... où nnnnn est une valeur numérique
Paramètre équivalent ligne de commande : --include= / --exclude=
Les ordres successifs (un par ligne) INCLUDE,EXCLUDE COND= sont traités avec un "ET" booléen.
INCLUDE COND=(1,5,CH,GT,N'100') INCLUDE COND=(1,5,CH,LT,N'500')est équivalent à :
INCLUDE COND=(1,5,CH,GT,100,AND,1,5,CH,LT,500)
Un ordre INCLUDE COND=() ou EXCLUDE COND=(...) ne fonctionne qu'avec un seul fichier en sortie.
Dès qu'il y a plusieurs fichiers en sortie, il faut appliquer la forme 3 :
Forme 3 : Filtrage sélectif, plusieurs fichiers en sortie
OUTFIL DD:variable,INCLUDE|EXCLUDE=(col,len,type,op,pattern[,AND|OR,col,len,type,op,pattern ...]) à partir de v6.92 : OUTFIL pathname,INCLUDE|EXCLUDE=(col,len,type,op,pattern[,AND|OR,col,len,type,op,pattern ...])
Les ordres EXCLUDE/INCLUDE sont compatibles avec VFIELDS à partir de la version 6.92.
EXCLUDE et OMIT sont synonymes.
Exemple 1 :
INCLUDE COND=(15,5,CH,EQ,C'JONES',OR,15,5,CH,EQ,C'SMITH') OMIT COND=(11,3,CH,EQ,C'000')
Ces deux ordres signifient :
- inclure les enregistrements dont le champs en col.15-19 contient 'SMITH' ou 'JONES'
- exclure de ces enregistrements ceux qui contiennent la valeur '000' en col. 11-13.
Exemple 2 :
SORT VFIELDS=(9,2,C,A,8,30,C,A,10,5,N,A),FIELDSEP=COMMA
RECORD RECFM=V,LRECL=400
; ---------------- Tous les clients:
OUTFIL DD:ALLCLIENTS
; ---------------- seulement les clients from New-York:
OUTFIL DD:NEWYORKERS,INCLUDE=(9,2,CH,EQ,C'NY')
; ---------------- Les autres clients en dehors de New-York:
OUTFIL D:\data\app1\others.csv,EXCLUDE=(9,2,CH,EQ,C'NY')
; ---------------- seulement les clients de Washingtown dont le nom commence par AB, CD, ou EF :
OUTFIL DD:WASHDC,INCLUDE=(9,2,CH,EQ,C'WA',AND,
(11,2,CH,EQ,C'AB',OR,
11,2,CH,EQ,C'CD',OR,
11,2,CH,EQ,C'EF'))
Ces trois ordres OUTFIL signifient :
- inclure tous les enregistrements dans le fichier défini par la variable d'environnement ALLCLIENTS
- inclure les enregistrements ayant le 9ème champ égal à "NY" dans le fichier défini par la variable d'environnement NEWYORKERS
- exclure ces enregistrements "NewYork" du fichier
D:\data\app1\others.csv - inclure les enregistrements ayant le 9ème champ égal à "NY" ET le 11ème champ commençant par "AB" ou "CD" ou "EF" dans le fichier défini par la variable d'environnement WASHDC
Voir des exemples de jobs XSM
Le paramètre OUTFILDUP
Le paramètre OUTFILDUP sert à indiquer un nom de fichier dans lequel seront écrits les doublons filtrés par OMIT DUPLICATE RECORDS ou OMIT DUPLICATE KEYSIl peut prendre 2 formes : nom de fichier ou variable :
OUTFILDUP /my/duplicate.file.txt
ou
OUTFILDUP DD:Myvariable
Paramètre équivalent ligne de commande : --outfiledup=
Par définition, seuls les enregistrements "doublons" sont écrits, mais pas l'enregistrement original qui a servi à comparer le(s) doublon(s).
Pour intégrér aussi ce premier enregistrement au fichier doublon, utiliser l'option WRITEFIRSTDUPLICATE ou l'option ligne de commande --outfiledup-record1
Le paramètre OUTREC
OUTREC sert à reformater un fichier en sortie. Il spécifie le dessin d'enregistrement en sortie.
Il ne peut y avoir qu'une seule instruction OUTREC.
S'il y a plusieurs fichiers en sortie, avec des filtres OUTFIL DD:xxx,INCLUDE=(...), alors le OUTREC s'appliquera à tous les fichiers en sortie.
le OUTREC traite l'enregistrement en sortie une fois trié et filtré ; donc le dessin d'enregistrement en sortie peut ne pas contenir les clés de tri.
Forme courte :
OUTREC FIELDS=(start,long[,start2,len2...])
start : position de départ
long : longueur
Paramètre équivalent ligne de commande : --outrec=
Forme longue :
OUTREC FIELDS=(start,long,type,offset[,start2,len2,type2,offset2...])
start : position de départ ou valeur de padding pour type=B, P, ou Z
long : longueur
type C : champ normal a copier
S : space : padding à blanc
B : byte : padding avec valeur de caractère indiquée en 'start'
P : Packed Decimal : padding avec valeur Packed Decimal indiquée en 'start'
Z : Zone Decimal : padding avec valeur Zoned Decimal indiquée en 'start'
offset : position en sortie
Padding :
Pour faire du padding avec un caractère donné, indiquez le type B
et indiquez le caractère de padding à la place du champ "start"
- soit sous forme de caractère,
- soit sous forme Hexadécimale,
- soit sous forme décimale.
Toutes les syntaxes suivantes sont équivalentes pour indiquer un padding en position 33 sur 10 avec le caractère 'A' :
Le début d'enregistrement, zone de 1 à 32, est automatiquement rempli avec des espaces ("blancs").
OUTREC FIELDS=(C'A',10,B,33)
OUTREC FIELDS=('A',10,B,33)
OUTREC FIELDS=(A,10,B,33)
OUTREC FIELDS=(X'45',10,B,33)
OUTREC FIELDS=(X45,10,B,33)
OUTREC FIELDS=(65,10,B,33)
OUTREC FIELDS=(D65,10,B,33)
OUTREC FIELDS=(D'65',10,B,33)
OUTREC FIELDS=(N65,10,B,33)
OUTREC FIELDS=(N'65',10,B,33)
Si le champ en entrée est plus long que la zone indiquée en sortie, alors le champs est tronqué
S'il s'agit de VFIELDS (champs à longueur variable avec séparateur), alors l'offset indique le rang en sortie.
Si nécessaire, l'enregistrement aura un padding avec le FIELDSEP défini
OUTREC FIELDS=(1,5,C,1,
2,5,C,12)
repositionne en sortie le 2ème champ en 12ème position :
Fichier en entrée :John;Smith;;123;Fichier en sortie :
John;;;;;;;;;;;;Smith;
Troncation :
Pour tronquer un enregistement, soit en RECFM=F ou RECFM=V, rajouter LRECL= + longueur voulue au paramètre OUTFIL.
Chaque définition de fichier en sortie OUTFIL peut avoir son propre LRECLRECORD RECFM=V,LRECL=300 ; input file specification ... OUTFIL DD:OUTNORMAL ; this file will use the input LRECL=300 OUTFIL DD:OUT_L40,LRECL=40 ; this file will have max 40 char record length OUTFIL DD:OUT_L100,LRECL=100 ; this file will have max 100 char record length
Exemples de reformatage
SORT FIELDS=(10,12,C,A) ; sort keys on pos 10, length 12, Character, Ascending RECORD RECFM=V,LRECL=200 ; input is variable length records ended with LR or CR/LF INPFIL /usr/include/stdint.h ; input file IOERROR IGNORE ; get rid of empty lines OUTFIL DD:SORTOUT,INCLUDE=(3,6,C,EQ,C'define') ; filters only ""# define ..." lines OUTREC FIELDS=(10,12,C,20) ; puts zone 10 to 21 at position 20Fichier en entrée : /usr/include/stdint.h
/* Limits of integral types. */ /* Minimum of signed integral types. */ # define INT8_MIN (-128) # define INT16_MIN (-32767-1) # define INT32_MIN (-2147483647-1) # define INT64_MIN (-__INT64_C(9223372036854775807)-1) ...Fichier en sortie :
INTMAX_MAX
INTMAX_MIN
INT_FAST64_M
INT_FAST64_M
INT_FAST8_MA
INT_FAST8_MI
INT_LEAST16_
INT_LEAST16_
...
Maintenant, rajoute un padding à '-' sur longueur 10, en position 1 :
OUTREC FIELDS=('-',10,B,1,
10,12,C,20)
Fichier en sortie:
---------- INTMAX_MAX ---------- INTMAX_MIN ---------- INT_FAST64_M ---------- INT_FAST64_M ---------- INT_FAST8_MA ---------- INT_FAST8_MI ---------- INT_LEAST16_ ---------- INT_LEAST16_ ...Maintenant, rajoute un Line Feed (1 byte, longueur 1) en position 23 :
OUTREC FIELDS=('-',10,B,1,
10,12,C,20,
X'0A',1,B,23)
Fichier en sortie:
---------- INT MAX_MAX ---------- INT MAX_MIN ---------- INT _FAST64_M ---------- INT _FAST64_M ---------- INT _FAST8_MA ---------- INT _FAST8_MI ---------- INT _LEAST16_ ---------- INT _LEAST16_ ...
Le paramètre SKIP_HEADER[S]
SKIP_HEADER nnn
SKIP_HEADERS nnn
Paramètre équivalent ligne de commande : --skip-header= --skip-headers=
Le paramètre SKIP_HEADER va ignorer les nnn premiers enregistrements (lignes) du premier fichier en entrée.
Le paramètre SKIP_HEADERS va ignorer les nnn premiers enregistrements (lignes) de chaque fichier en entrée.
Si un filtre EXCLUDE/INCLUDE est utilisé, le filtre s'applique aux enregistrements restant après suppression des nnn 1ers enregistrements par SKIP_HEADER.
SKIP_HEADER et SKIP_HEADERS sont mutuellement exclusifs.
Exemple :SKIP_HEADER 4 # throw away report header
Voir un exemple de jobs XSM avec SKIP_HEADER
Le paramètre OPTION
OPTION option1,option2,...
ou
OPTIONS option1,option2,...
où les options sont :
Cette option n'a de sens que pour les champs de 2 caractère de type 'Y' ou 'Y2K';
(Voir ci-dessous le paramètre 'FIELDS')
ou
COLLATE=EBCDIC
Elle garde l'ordre lexicographique EBCDIC pour les clés de tri ASCCI, à savoir :
- d'abord les minuscules,
- puis les majuscules,
- et enfin les chiffres.
ou
RSEP=hex_string
Cette option est principalement utilisée par les systèmes OPEN MVS et OS/400 pour les fichiers à longueur variables.
Elle définie le caractère (1 octet) délimitant les enregistrements.
Par défaut:
RSEP=0D0A (Windows)
RSEP=X15 (Open MVS)
RSEP=X25 (OS/400)
OPTION RSEP=| ou OPTION RSEP=7CParamètre équivalent ligne de commande : --record-separator=
ou
PROCESSORS=n
ou
PROCS=n
Par exemple, si vous avez une machine moderne 8-CPU, vous pouvez inclure cette option dans les parmfiles, afin d'augmenter les performances :
OPTION PROCS=8
En général, laisser XSM décider seul de l'usage optimal des ressources.
Paramètre équivalent ligne de commande : --procs=ou
KEEPORDER=Y|N
ou
EQUALS
Cf. explications sur le tri stable ci-dessous. Paramètre équivalent ligne de commande : --keep-order
Cette option permet de copier partiellement ou complètement le fichier en entrée dans un ou plusieurs fichiers en sortie.
Les parametres COPY suivants sont équivalents, pour compatibilité IBM DF/SORT :
OPTION COPY
ou
SORT FIELDS=COPY
ou
COPY
Paramètre équivalent ligne de commande : --copy
L'option COPY peut être suivie d'un ou plusieurs paramètres OUTFIL :
OUTFIL DD:variable ; équivalent à OUTFIL DD:variable,INCLUDE=ALL ou OUTFIL DD:variable,INCLUDE|EXCLUDE=(condition1[,AND/OR,condition2...])Cf. le paramètre 'OUTFIL' ci-dessous. Cf. exemple de job avec COPY et sorties sélectives DD:...,INCLUDE=(...)
ou
WRITEFIRSTDUP
Avec cette option "Write First Duplicate", ce premier enregistrement est également écrit dans le fichier doublons.
OMIT DUPKEYS
# Fichier en sortie, dédoublonné :
OUTFIL myoutput.txt
# fichier des doublons :
OUTFILDUP mesdoublons.txt
# force a écrire également le premier enregistrement qui va rencontrer un doublon
OPTION WRITEFIRSTDUPLICATE
Paramètre équivalent ligne de commande : --outfiledup-record1 ou --dup-rec1
soit le fichier suivant en entrée, trié sur nom, prénom :
01234001 JOHN PALMER 05678001 BOB JOHNSON 01234002 JOHN PALMER 05678002 BOB JOHNSON 06095300 KAREN SMITHRésultat du fichier doublons (OUTFILDUP mesdoublons.txt) sans l'option WRITEFIRSTDUPLICATE :
01234002 JOHN PALMER 05678002 BOB JOHNSONRésultat du fichier doublons (OUTFILDUP mesdoublons.txt) avec l'option WRITEFIRSTDUPLICATE :
05678001 BOB JOHNSON 05678002 BOB JOHNSON 01234001 JOHN PALMER 01234002 JOHN PALMER
Exemple d'utilisation du paramètre OPTION:
OPTION PROCS=4,KEEP_ORDER=Y # force multithreading on 4 procs, force stable sort
Le paramètre IOERROR
IOERROR IGNORE
Paramètre équivalent ligne de commande : --ignore-ioerror
Le paramètre IOERROR n'a de sens que pour les fichiers de texte à enregistrements de longueur variable (RECFM=V).
Il indique à XSM que faire lorsqu'une ligne est plus courte que les clés définies:
- S'il est absent, la 1ere ligne plus courte que les clés de tris causera l'arrêt en erreur de XSM immédiatement.
- S'il est présent, les erreurs dues aux lignes trop courtes seront ignorées.
Le paramètre SORTWORKS
SORTWORKS répertoire1[,répertoire2,...]
répertoire : liste des répertoires de manoeuvre
Paramètre équivalent ligne de commande : --sortworks=
Le Paramètre SORTWORKS indique quel(s) répertoire(s) de manoeuvre utiliser pour les fichier temporaires
Exemples :SORTWORKS C:\TMP,D:\TEMP (Windows) SORTWORKS /var/tmp,/tmp (UNIX)
Le Paramètre SORTWORKS est optionnel. Par défaut, le répertoire courant est utilisé.
*** l'utilisation de SORTWORKS est essentielle pour les performances ***
Lorsque plusieurs sortworks sont spécifiés, XSM force le traitement multi-threading : un thread par répertoire.
Lorsque les deux paramètres OPTION PROCS= et SORTWORKS=dir1,dir2,...,dirn sont spécifiés, XSM utilise la plus grande des deux valeurs pour le nombre de threads.
Utiliser des sortworks sur un disque physique autre que celui contenant les fichiers en entrée et en sortie va augmenter de façon notoire les performances XSM en réduisant les contentions d'I/O concurrentes sur un même disque.
En effet, pour simplifier, considérons que les phases XSM d'I/O sont :
Phase 1 : lecture fichier input + écriture sortworks ------------------------------------------------------------------------- Phase 2 : lecture sortworks + écriture fichier outputLa combinaison input + output sur un même disque, sortworks sur un autre disque va produire les meilleurs résultats :
(Disk1) (Disk2)
Phase 1 : lecture fichier input Read
+ écriture sortworks Write
-------------------------------------------------------------------------
Phase 2 : lecture sortworks Read
+ écriture fichier output Write
La combinaison input + sortworks sur un même disque, output sur un autre disque va produire de mauvais résultats :
(Disk1) (Disk2)
Phase 1 : lecture fichier input Read
+ écriture sortworks Write <==  Concurrent I/O on same disk: BAD!
-------------------------------------------------------------------------
Phase 2 : lecture sortworks Read
+ écriture fichier output Write
Concurrent I/O on same disk: BAD!
-------------------------------------------------------------------------
Phase 2 : lecture sortworks Read
+ écriture fichier output Write
Illustration de la même opération, l'une avec 1 seul disque, l'autre avec 2 disques:
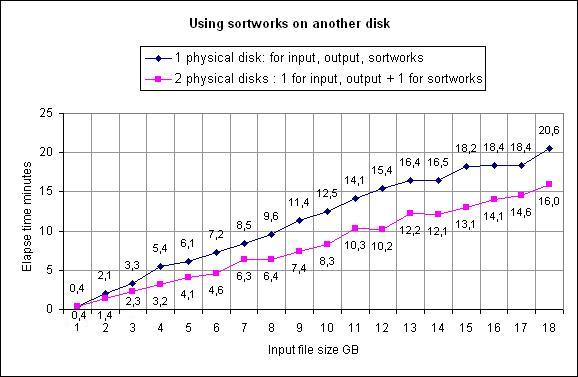
Notez que les résultats dépendent grandement de facteurs tels que: taille des fichiers,
free memory, vitesse disques, vitesse CPU.
Le graphe ci-dessus illustre simplement que l'utilisation de disques physiques différents accroît de façon certaine les performances.
Les fichiers temporaires sont nommés d'après le Process Id XSM, par exemple srtw04d2.xxx
pour le Pid 1234 (hexa 04d2). L'exécution simultanée de plusieurs XSM sur les mêmes
répertoires SORTWORKS n'est pas un problème.
Les fichiers temporaires sont supprimés en fin de job. En cas d'erreur sévère, il se peut qu'ils ne soient pas supprimés. Aussi il est conseillé de contrôler le code retour XSM.
Voir des exemples de jobs XSM
Le paramètre STORAGE
STORAGE size{K|M|G}
size : quantité de mémoire centrale à utiliser, en KiloOctets, MegaOctets, ou GigaOctets.
Exemples :
STORAGE 450K
STORAGE 2150K
STORAGE 8M
Paramètre équivalent ligne de commande : --storage=
Le paramètre STORAGE est optionnel. Il est calculé automatiquement par XSM, en fonction du Système d'Exploitation et des fichiers à traiter.
Pour les très gros fichiers, il permet dans certains cas de limiter la pagination, et éviter le System Stress qui en découle :
T = taille totale input en MegaOctets
T ≤ 64517 MB : STORAGE = Racine Carrée( T ) / 4
T > 64517 MB : STORAGE = T / 1020
Par exemple, 3 fichiers en entrée de 25000 MB :
T = 3 x 25000 = 75000 (MB)
STORAGE = 75000 / 1020 = 74MB
STORAGE 74MB peut améliorer les performances.
En général, il est recommandé de laisser XSM calculer les valeurs optimales de ressources.
5. Syntaxe ligne de commande
Le programme de Tri/Fusion XSM se lance depuis une ligne de commande, sous Windows, Linux, UNIX.
XSM peut être appelé avec ou sans fichier paramètres.
Une fois les paramètres et options mises au point, intégrez la ligne de commande dans vos programmes batchs : Shell UNIX, .bat Windows ou toute autre langage procédural de votre choix.
La syntaxe complète s'affiche lorsque l'on lance XSM sans paramètre,ou avec le paramètre --help :
hxsm [options]
Options:
-c, --check Option de vérification. Ne fait que vérifier le résultat d'une
opération de tri/fusion antérieure et affiche le message :
"XSM064I The file xxx correctly sorted" en cas de succes.
-q, --quiet Mode silencieux : aucune information sur stderr sauf si une erreur se produit.
Noter que stdout est réservé pour la sortie par défaut si aucun fichier en sortie
n'est spécifié.
-v, --verbose Affiche les détails durant le traitement.
-v/--verbose et -q/--quiet sont mutuellement exclusifs.
-vv, --veryverbose Affiche plus de détails durant le traitement.
-h, --help Affiche le mode d'emploi et s'arrête.
--sort Opération "tri" (par défaut).
Paramètre Parmfile équivalent : SORT
-m, --merge Opération "fusion".
Paramètre Parmfile équivalent : MERGE
--copy Opération "copie".
Paramètre Parmfile équivalent : OPTION COPY
--sort --merge --copy sont mutuellement exclusifs
-k, --key=start,len[,direction,[type] ]
Définition des clés de tri :
start : position début (commence à 1) de la clé
length : longueur de la clé, en octets
direction : 'D' = descendant, 'A' = ascendant
type : 'C' = caractère
'B' = octet binaire ("low value" en Cobol)
'I' = ignore casse Majuscule/minuscule
'N' = numérique
'P' = champ Décimal Packé
(seulement pour fichiers en RECFM=F ou M)
'Y' = année d'une date
Paramètre Parmfile équivalent : SORT FIELDS=(start,len,dir,type)
-k all, --key=all Tri avec clé = l'enregistrement entier
Paramètre Parmfile équivalent : SORT FIELDS=ALL
-r, --recfm=F|V|M Indique le format d'enregistrement (RECord ForMat) :
F (Fixed), V (variable), M (MFCobol)
Par défaut : V (variable)
Paramètre Parmfile équivalent : RECORD RECFM=
-l nnn, --lrecl=nnn Indique la longueur logique d'enregistrement (Logical ReCord Length):
nnn = longueur exacte d'enregistrement pour RECFM=F, y compris un séparateur CR/LF
nnn = longueur max. d'enregistrement pour RECFM=V, sans compter le séparateur de
ligne CR/LF
-z nnn Identique à -l nnn (Pour compatibilité sort UNIX)
Paramètre Parmfile équivalent : RECORD LRECL=
--infile=filein[,recfm=F|V|M[,lrecl=nnn] Spécifie le(s) fichier(s) en entrée
RECFM et LRECL peuvent être spécifiés avec un fichier en entrée lors d'un
reformatage.
Cf. Reformatage
Plusieurs fichiers en entrée peuvent être spécifiés ainsi :
--infile=/tmp/f1 --infile=/tmp/f2 ...
Paramètre Parmfile équivalent : INPFIL
-o, --outfile=fileout[,recfm=F|V|M[,lrecl=nnn]] Spécifie le fichier en sortie
RECFM et LRECL peuvent être spécifiés avec un fichier en sortie lors d'un
reformatage.
Cf. Reformatage
Paramètre Parmfile équivalent : OUTFIL
--outrec=(pos,len[,p2,l2,...])
--outrec=(pos,len,type,offset[,p2,l2,t2,o2,...])
Spécifie le dessin d'enregistrement en sortie lors d'un reformatage.
Cf. Reformatage
Paramètre Parmfile équivalent : OUTREC
-uk, --unique-key Supprime les prochains enregistrements avec clés doublons, le 1er est conservé
Paramètre Parmfile équivalent : OMIT DUPLICATE KEYS
-ur, --unique-record Supprime les prochains enregistrements doublons, le 1er est conservé
Paramètre Parmfile équivalent : OMIT DUPLICATE RECORDS
--outfiledup=fileout Spécifie le fichier en sortie pour les doublons *** v6.94 ***
Paramètre Parmfile équivalent : OUTFILDUP
--outfiledup-record1 Inclut dans le fichier doublons le premier enregistrement qui à l'origine du
--dup-rec1 doublon. Sinon, seuls les prochains doublons seront écris dans le fichier
doublons. cf exemple. *** v6.94 ***
Paramètre Parmfile équivalent : OPTION WRITEFIRSTDUPLICATE
--include=start,len,op,val[AND|OR,start,len,op,val...]
Spécifie un filtre "inclure"
Paramètre Parmfile équivalent : INCLUDE
--exclude=start,len,op,val[AND|OR,start,len,op,val...]
Spécifie un filtre "exclure"
Paramètre Parmfile équivalent : EXCLUDE
-t dir1,dir2 --sortwork[s]=dir1,dir2,...
Spécifie la liste de répertoires de manoeuvre
On peut spécifier une liste de répertoires séparés par une virgule (,)
ou plusieurs options --sortworks= ou -t :
--sortworks=/tmp1/dir1 --sortworks=/tmp/dir2
équivalent à :
--sortworks=/tmp1/dir1,/tmp/dir2
équivalent à :
-t /tmp1/dir1 -t /tmp/dir2
équivalent à :
-t /tmp1/dir1,/tmp/dir2
Paramètre Parmfile équivalent : SORTWORKS
-y nnnK|M|G, --storage=nnnK|M/G Force l'allocation en mémoire centrale à nnn Kilo/Méga/GigaOctets
Dans la plupart des cas, il est recommandé de laisser XSM faire lui-même le calcul
A n'utiliser que lors de traitements lents sur des gros fichiers
Paramètre Parmfile équivalent : STORAGE
--keep-order Force le mode de tri non-destructif, également nommé "stable sort"
Cf. explications ci-dessous
Paramètre Parmfile équivalent : OPTION KEEP_ORDER
--record-separator=C|0xhh Défini les caractères ou paires de caractères séparateurs d'enregistrements
Principalement utilisé pour les fichiers variables sous OPEN MVS et OS/400
Paramètre Parmfile équivalent : OPTION RECORD_SEPARATOR
--collating-sequence=ebcdic force la séquence alphanumérique à IBM EBCDIC
Paramètre Parmfile équivalent : OPTION COLLATING
--skip-header=nnn Ignore les nnn premiers enregistrement du premier fichier en entrée
Paramètre Parmfile équivalent : SKIP_HEADER
--skip-headers=nnn Ignore les nnn premiers enregistrement de chaque fichier en entrée
Paramètre Parmfile équivalent : SKIP_HEADERS
--throw-empty-records Ignore les enregistrements vides. Sans cette option, XSM s'arrête en erreur
lorsqu'il rencontre un enregistrement vide (taille=0) en entrée.
-i, --ignore-ioerror Ignore les lignes de longueur plus courtes que les clés de tri
(fichiers texte RECFM=V seulement)
Paramètre Parmfile équivalent : IOERROR IGNORE
-n n, --procs=n Force le multi-threading à n Threads
Paramètre Parmfile équivalent : OPTION PROCS
--norun Teste la syntaxe d'un fichier paramètres, sans exécuter le traitement
v6.94 ***
Paramètre Parmfile équivalent : OUTFILDUP
--outfiledup-record1 Inclut dans le fichier doublons le premier enregistrement qui à l'origine du
--dup-rec1 doublon. Sinon, seuls les prochains doublons seront écris dans le fichier
doublons. cf exemple. *** v6.94 ***
Paramètre Parmfile équivalent : OPTION WRITEFIRSTDUPLICATE
--include=start,len,op,val[AND|OR,start,len,op,val...]
Spécifie un filtre "inclure"
Paramètre Parmfile équivalent : INCLUDE
--exclude=start,len,op,val[AND|OR,start,len,op,val...]
Spécifie un filtre "exclure"
Paramètre Parmfile équivalent : EXCLUDE
-t dir1,dir2 --sortwork[s]=dir1,dir2,...
Spécifie la liste de répertoires de manoeuvre
On peut spécifier une liste de répertoires séparés par une virgule (,)
ou plusieurs options --sortworks= ou -t :
--sortworks=/tmp1/dir1 --sortworks=/tmp/dir2
équivalent à :
--sortworks=/tmp1/dir1,/tmp/dir2
équivalent à :
-t /tmp1/dir1 -t /tmp/dir2
équivalent à :
-t /tmp1/dir1,/tmp/dir2
Paramètre Parmfile équivalent : SORTWORKS
-y nnnK|M|G, --storage=nnnK|M/G Force l'allocation en mémoire centrale à nnn Kilo/Méga/GigaOctets
Dans la plupart des cas, il est recommandé de laisser XSM faire lui-même le calcul
A n'utiliser que lors de traitements lents sur des gros fichiers
Paramètre Parmfile équivalent : STORAGE
--keep-order Force le mode de tri non-destructif, également nommé "stable sort"
Cf. explications ci-dessous
Paramètre Parmfile équivalent : OPTION KEEP_ORDER
--record-separator=C|0xhh Défini les caractères ou paires de caractères séparateurs d'enregistrements
Principalement utilisé pour les fichiers variables sous OPEN MVS et OS/400
Paramètre Parmfile équivalent : OPTION RECORD_SEPARATOR
--collating-sequence=ebcdic force la séquence alphanumérique à IBM EBCDIC
Paramètre Parmfile équivalent : OPTION COLLATING
--skip-header=nnn Ignore les nnn premiers enregistrement du premier fichier en entrée
Paramètre Parmfile équivalent : SKIP_HEADER
--skip-headers=nnn Ignore les nnn premiers enregistrement de chaque fichier en entrée
Paramètre Parmfile équivalent : SKIP_HEADERS
--throw-empty-records Ignore les enregistrements vides. Sans cette option, XSM s'arrête en erreur
lorsqu'il rencontre un enregistrement vide (taille=0) en entrée.
-i, --ignore-ioerror Ignore les lignes de longueur plus courtes que les clés de tri
(fichiers texte RECFM=V seulement)
Paramètre Parmfile équivalent : IOERROR IGNORE
-n n, --procs=n Force le multi-threading à n Threads
Paramètre Parmfile équivalent : OPTION PROCS
--norun Teste la syntaxe d'un fichier paramètres, sans exécuter le traitement
Options courtes et longues peuvent être combinées dans la commande, comme suit :
hxsm --input-file=/tmp/f.in -o/tmp/f.out myparms.xsmPour un démarrage facile, consultez les exemples de tris ci-dessous, qui fonctionnent indifféremment sous Windows, Linux, UNIX :
6. Exemples de tris : La meilleure façon de commencer !
Job 1 : Un fichier texte
- Les lignes sont de 200 car. maxi (sans compter le CR/LF)
- La clé de tri est un champ en colonnes 14-20, de longueur = 20 - 14 + 1 = 7
Le fichier ressemble à :0 1 1 2 3 0123456789012345678901234567890123456 ... |....+....|....+....|....+....|....+..... ABCDEF PARIS 001HHNS A123456 2010-12-31... [ clé ] : débute en col 14, se termine en col 20 - le fichier en entrée est 'SAMPLE.INP'
- le fichier en sortie est 'SAMPLE.OUT'
Méthode 1 : Les fichiers entrée/sortie sont spécifiés en utilisant le style de redirection UNIX
Ligne de commande complète sans fichier paramètres :
hxsm --recfm=V --lrecl=200 --key=14,7,A < SAMPLE.INP > SAMPLE.OUT
ou
hxsm -r V -l 200 -k 14,7,A < SAMPLE.INP > SAMPLE.OUT
Ligne de commande avec un fichier paramètres :
hxsm job1.xsm < SAMPLE.INP > SAMPLE.OUTFichier paramètres job1.xsm :
SORT FIELDS=(14,7,C,A) ; one sort key in position 14, length 7, type Char, Ascending RECORD RECFM=V,LRECL=200 ; Variable length, maximum expected length is 200
Méthode 2: Les fichiers entrée/sortie sont "en dur" dans le parmfile
Fichier paramètres job1.xsm :SORT FIELDS=(14,7,B,A) ; one sort key in position 14, length 7, type Binary, Ascending RECORD RECFM=V,LRECL=200 ; Variable length, maximum expected length is 200 INPFIL SAMPLE.INP ; Input file OUTFIL SAMPLE.OUT ; Output fileLigne de commande avec un fichier paramètres :
hxsm -vv job1.xsm
Méthode 3: Ligne de commande complète sans fichier paramètres
hxsm -vv -k 14,7 -l 200 < SAMPLE.INP > SAMPLE.OUT
ou
hxsm -vv -k 14,7 -l 200 -o SAMPLE.OUT SAMPLE.INP
ou
hxsm -vv --key=14,7 --lrecl=200 --outfile=SAMPLE.OUT --infile=SAMPLE.INP
Job 2 : Un fichier texte, redirection du flux stdout
- Identique au job précédent, mais la sortie est redirigée vers un programme 'MYREPORT.EXE'
# Job 2 : OUTFIL n'est pas spécifié : XSM écrira sur 'stdout' # Utilisé pour rediriger la sortie directement à un programme SORT FIELDS=(14,7,B,A) RECORD RECFM=V,LRECL=200 INPFIL SAMPLE.INPLigne de commande :
hxsm -vv job2.xsm | myreportLigne de commande complète sans fichier paramètres :
hxsm -vv -k 14,7 -i SAMPLE.INP | myreportPour supprimer les enregistrements doublons ("dédoublonner"), ajouter l'option -ur (ou --unique-record) :
hxsm -vv -ur -k 14,7 -i SAMPLE.INP | myreport ou hxsm -vv --unique-record --key=14,7 --infile=SAMPLE.INP | myreport
Job 3 : Un fichier texte, redirection des flux stdin, stdout
- Identique au job précédent, mais l'entrée provient d'un programme de comptabilité 'MYACCOUNT.EXE'
# Job 3 : ni INPFIL ni OUTFIL ne sont spécifiés : # Les redirections au style UNIX sont utilisées à la place SORT FIELDS=(14,7,B,A) RECORD RECFM=V,LRECL=200Ligne de commande :
myaccount | hxsm job3.xsm | myreportLigne de commande complète sans fichier paramètres :
myaccount | hxsm -k 14,7 | myreport
Job 4 : Deux fichiers binaires, sortworks sur disques différents pour optimiser les I/O
- Les enregistrements sont de longueur 180
- Les clés de tri sont le numéro comptable en col. 14 à 20, et une date 'aammjj' en col 2 à 7
- La 1ere clé est en ordre descendant, la seconde en ordre ascendant
- Les fichiers en entrée sont '../s1' and '../s2', chacun fait environ 4 Mégaoctets
- Le fichier en sortie est '/usr/acct/sample.out'
- On utilise 2 répertoires temporaires situés sur 2 disques différents pour optimiser les I/O.
Cf. discussion sur les Sortworks pour comprendre l'intérêt.
# job4.xsm : XSM parameter file for job4 #------------ Sort keys : SORT FIELDS=(14,20,B,A,2,6,B,D) RECORD RECFM=F,LRECL=180 #------------ input/output files: INPFIL ../s1 ; input file #1 INPFIL ../s2 ; input file #2 OUTFIL /usr/acct/sample.out ; output file #------------ temp files : SORTWORKS /drive1/tmp,/drive2/tmp ; 2 sortwork directoriesLigne de commande :
hxsm -vv job4.xsmLigne de commande complète sans fichier paramètres, style options courtes:
hxsm -vv -k 14,20 -k 2,6,d -r F -z 180 \
-t /var/tmp,/tmp \
-o /usr/acct/sample.out ../s1 ../s2
La même chose en style options longues (plus facile à lire) :
hxsm -vv --key=14,20 --key=2,6,d --recfm=F --lrecl=180 \
--sortwork=/var/tmp,/tmp \
--outfile=/usr/acct/sample.out \
--infile=../s1 --infile=../s2
Job 5 : Deux fichiers binaires, filtrage des enregistrements par OMIT
- Identique au job précédent, mais seuls les enregistrements commençants par '*' sont à prendre en compte
# job5.xsm : XSM parameter file for job5 #------------ Sort keys : SORT FIELDS=(14,20,B,A,2,6,B,D) RECORD RECFM=F,LRECL=180 #------------ input/output files: INPFIL ../s1 ; input file #1 INPFIL ../s2 ; input file #2 OUTFIL /usr/acct/sample.out ; output file #------------ temp files : SORTWORKS /drive1/tmp,/drive2/tmp ; 2 sortwork directories #------------ filters : OMIT COND=(1,1,CH,EQ,'*') ; exclude records with character '*' on position 1Ligne de commande avec fichier paramètres :
hxsm -vv job5.xsmLigne de commande complète sans fichier paramètres :
hxsm -vv --key=14,20 --key=2,6,d --recfm=F --lrecl=180 \
--sortwork=/var/tmp,/tmp \
--outfile=/usr/acct/sample.out \
--infile=../s1 --infile=../s2 \
--exclude="1,1,C,'*'"
Job 6 : Un fichier texte type CSV à champs de longueur variable avec séparateur de champs
- Les enregistrements sont de longueur maxi 100, sans compter les séparateurs de ligne LF (UNIX) ou CR/LF (Windows)
- 1ere clé : un nom, 3eme champ, long. max 40 car., case non sensitive, ordre ascendant
- 2eme clé : un numérique, 2eme champ, long. max 10 digits, ordre descendant
- suppression des lignes avec clés dupliquées, sauf la 1ere.
SORT VFIELDS=(3,40,I,A,2,10,N,D),FIELDSEP=SEMICOLUMN ; Variable length fields delimited by ';' RECORD RECFM=T,LRECL=100 INPFIL C:\data\myfile.csv OUTFIL D:\data\myfile_sorted.csv OMIT DUPKEYS ; raccourci de OMIT DUPLICATE KEYS
Note : Pour définir le séparateur de champs, l'utilisation de symboles SEMICOLUMN, COMMA, etc... est recommandée afin d'éviter toute erreur d'analyse syntaique du parmfile. cf. syntaxe FIELDSEP=.
Ligne de commande :hxsm -vv job6.xsmPas d'équivalent ligne de commande complète, à cause du VFIELD
Job 7 : Un fichier binaire contenant des zones "Packed Decimal"
- Les enregistrements sont de longueur fixe 110,
- 1ere clé : pos 1 à 4, type "Packed Decimal", ordre descendant,
- 2eme clé : pos 21 à 40, alphanumérique, ordre descendant
SORT FIELDS=(1,4,P,D,21,20,B,A) ; type P means Packed decimal RECORD RECFM=F,LRECL=110 INPFIL E:\tmp\s1.bin OUTFIL E:\tmp\s2.binLigne de commande :
hxsm -vv job7.xsmLigne de commande complète sans fichier paramètres :
hxsm -vv -r F -l 110 -k 1,4,P,D -k 21,20 -o E:\tmp\s2.bin E:\tmp\s1.binLa même chose avec options longues :
hxsm -vv --recfm=F --lrecl=110 --key=1,4,P,D --key=21,20 --outfile=E:\tmp\s2.bin --infile=E:\tmp\s1.bin
Job 8 : Un fichier texte avec des champs dates au format 'mmjjaa', changement du pivot de siècle Y2K
- Les enregistrements sont de longueur maxi 110, sans compter les séparateurs de ligne LF (UNIX) ou CR/LF (Windows)
- 1ere clé pos. 1-4, Alphanumérique, ordre ascendant,
- 2eme clé pos. 21-40 Alphanumérique, ordre ascendant,
- 3eme clé pos. 61-66 date format 'mmjjaa', ordre descendant
- la plus vielle année antérieure est 1970 (default pivot Y2K).
SORT FIELDS=(1,4,BI,A,21,20,BI,A,65,2,Y2K,D,63,2,BI,D,61,2,BI,D) RECORD RECFM=V,LRECL=110 INPFIL /tmp/s1.txt OUTFIL /tmp/s2.txtLigne de commande :
hxsm -vv job8.xsmPas d'équivalent ligne de commande complète, à cause du type Y2K Pour changer le pivot par défaut Y2K = 1970 et considérer des dates avec AA < 70 (1970) comme appartenant au 21ème siècle (20xx) au lieu du 20ème siècle, ajouter le paramètre pivot Y2K:
OPTION Y2KSTART=19nn Exemple : OPTION Y2KSTART=1963 # changement du pivot 20e / 21e siècle de 1970 à 196364, 65, .... 99 seront considérées comme 19nn
00, 01, ... 63 seront considérées comme 20nn
Cf. FAQ, Y2K pour des explications sur le pivot Y2K.
Job 9 : Plusieurs fichiers texte avec identification et élimination des doublons
- Les enregistrements sont de longueur maxi 100, sans compter les séparateurs de ligne LF (UNIX) ou CR/LF (Windows)
- Les enregistrements avec clés identiques (doublons) sont éliminés
- En entrée on fusionne un fichier "mensuel" et un fichier "Quotidien"
Fichier en entrée data.monthly.2020.04.txt :
00001 PALMER JOHN 0012343445T46767878 00002 JOHNSON BOB 04E3293223235454654 00003 SMITH KAREN 0012343345665766887 00004 PALMER MIKE 0432434545657675606 00005 SMITH JACK 0046546507675465778 |
Fichier en entrée data.daily.2020.04.05.txt :
00001 PALMER MIKE 0432434545657675606 00002 SMITH KAREN 0012343345665766887 00003 WOOD PAUL 0343256556560767657 |
#0001 PALMER JOHN # | | # pos 10 pos 20 # | | SORT FIELDS=(10,10,C,A,20,10,C,D) # sort keys : Last Name, First Name RECORD RECFM=V,LRECL=100 # Adds daily data to monthly data : INPFIL data.monthly.2020.04.txt # Monthly input INPFIL data.daily.2020.04.05.txt # Daily input OUTFIL data.monthly.deduplicated.2020.04.txt # Montly deduplicated data OMIT DUPLICATE KEYS OUTFILDUP data.monthly.duplicated.2020.04.txt # Montly duplicated dataLigne de commande avec un fichier paramètres :
hxsm -vv dedup.xsmLigne de commande complète sans fichier paramètres :
hxsm -vv --recfm=V --lrecl=100 --key=10,10,A --key=20,10,D \
--infile=data.monthly.2020.04.txt \
--infile=data.daily.2020.04.05.txt \
--outfile=data.monthly.deduplicated.2020.04.txt \
--unique-key \
--outfiledup=data.monthly.duplicated.2020.04.txt
Execution XSM :
XSM056I HXSM V6.94-64 - (C) HH&S 1996-2020, Build Jul 5 2020 XSM096I Parameter file dedup.xsm loaded. 7 valid statements XSM096I key # 1 start 10, len 10, order ASCEND , type CHAR XSM096I key # 2 start 20, len 10, order DESCEND, type CHAR XSM027I Initializing ... XSM096I Using 2 nCPU, 4 Threads XSM089I Memory Total 2005 MB, Free 1614 MB XSM024I Using 0 work dir., 1 x 176 KB XSM028I Reading XSM073I 8 records processed, so far 8 : 0 sec. XSM015I Input: --------------------------------------------------------------- XSM014I 5 rec read from data.monthly.2020.04.txt XSM014I 3 rec read from data.daily.2020.04.05.txt XSM014I 8 rec read total XSM015I Filters: --------------------------------------------------------------- XSM014I 2 rec dropped on duplicate key XSM015I Output: --------------------------------------------------------------- XSM014I 2 rec with duplicate key written to data.monthly.duplicated.2020.04.txt XSM014I 6 rec written to data.monthly.deduplicated.2020.04.txt XSM014I 6 rec written total XSM031I End of Job dedup.xsm 6 rec. : 0 sec.Résultat :
|
Fichier en sortie contenant les données dédupliquées :
data.monthly.deduplicated.2020.04.txt : 00002 JOHNSON BOB 04E3293223235454654 00001 PALMER MIKE 0432434545657675606 00001 PALMER JOHN 0012343445T46767878 00003 SMITH KAREN 0012343345665766887 00005 SMITH JACK 0046546507675465778 00003 WOOD PAUL 0343256556560767657 |
Fichier en sortie contenant les doublons :
data.monthly.duplicated.2020.04.txt : 00004 PALMER MIKE 0432434545657675606 00002 SMITH KAREN 0012343345665766887 |
--outfiledup-record1
ou rajouter dans le parmfile le paramètres
OPTION WRITEFIRSTDUPLICATESans cette option, seuls les doublons seront écrits dans le fichier doublons. Voir Exemple
Job 10 : Copie d'un fichier avec éclatement sélectif sur plusieurs fichiers
- le nom des fichiers en entrée et en sortie provient de variables d'environnement
- Les enregistrements sont de longueur maxi 152, sans compter les séparateurs de ligne LF (UNIX) ou CR/LF (Windows)
- toutes les lignes sont copiées dans le fichier n. 1
- seules les lignes commençant par 'SCOTT' et contenant 'TIGER' en col. 16-20 sont copiées vers le fichier n. 2
- les autres lignes sont copiées vers le fichier n. 3
- la variable contenant le fichier en entrée est SORTIN (le nom de la variable est libre)
- les variables contenant les fichiers en sortie sont respectivement SORTOF1, SORTOF2, SORTOF3 (syntaxe obligatoire :
SORTOF+ un nombre commençant à 1)
Notez que l'usage de DD:varname impose que la variable d'environnement varname soit initialisée avant l'appel de XSM.
La forme DD:varname peut être utilisée à la fois pour les paramètres INPFIL et OUTFIL.
Fichier Paramètres job10.xsm :
OPTION COPY RECORD RECFM=V,LRECL=152 ; excluding CR/LF INPFIL DD:DATAIN OUTFIL DD:DATAOUT1,INCLUDE=ALL OUTFIL DD:DATAOUT2,INCLUDE=(1,5,CH,EQ,'SCOTT',AND,16,5,CH,EQ,'TIGER') OUTFIL DD:DATAOUT3,INCLUDE=(1,5,CH,NE,'SCOTT',OR,16,5,CH,NE,'TIGER') OMIT DUPRECSLigne de commande (UNIX) :
DATAIN=/tmp/myappl/data_to_copy.text \ DATAOUT1=/tmp/s1 \ DATAOUT2=/tmp/s2 \ DATAOUT3=/tmp/s3 \ hxsm -vv job10.xsmLigne de commande (Windows) :
setlocal set DATAIN=C:\tmp\myappl\data_to_copy.text set DATAOUT1=D:\tmp\s1 (or \tmp\s1 ...) set DATAOUT2=D:\tmp\s2 set DATAOUT3=D:\tmp\s3 hxsm -vv job10.xsm
Pas d'équivalent ligne de commande complète, à cause des formes DD:varname,INCLUDE=(...)
Job 11 : Tri d'un fichier avec éclatement sélectif sur plusieurs fichiers
- Identique au job précédent, mais la copie (
OPTION COPY) est remplacée par un tri (SORT FIELDS=) :
Fichier Paramètres job11.xsm :
SORT FIELDS=(1,5,C,A,16,5,C,A) RECORD RECFM=V,LRECL=152 ; sans compter CR/LF INPFIL DD:SORTIN OUTFIL DD:OUT1,INCLUDE=ALL OUTFIL DD:OUT2,INCLUDE=(1,5,CH,EQ,'SCOTT',AND,16,5,CH,EQ,'TIGER') OUTFIL DD:OUT3,INCLUDE=(1,5,CH,NE,'SCOTT',OR,16,5,CH,NE,'TIGER') OMIT DUPRECSLigne de commande (UNIX) :
SORTIN=/tmp/myappl/data_to_split.text \ OUT1=/tmp/s1 \ OUT2=/tmp/s2 \ OUT3=/tmp/s3 \ hxsm -vv job11.xsm
Pas d'équivalent ligne de commande complète, à cause des formes DD:varname,INCLUDE=
Job 12 : Tri/Fusion de fichiers et éclatement sélectif sur plusieurs fichiers
- Identique au job précédent, mais 3 fichiers en entrée au lieu de 1 :
Fichier Paramètres job12.xsm :
SORT FIELDS=(1,5,C,A,16,5,C,A) RECORD RECFM=V,LRECL=152 ; excluding CR/LF INPFIL DD:MYINPUT1 ; variable name is free with DD: form INPFIL DD:MYINPUT2 ; variable name is free with DD: form INPFIL DD:MYINPUT3 ; variable name is free with DD: form OUTFIL DD:MYOUTPUT1,INCLUDE=ALL OUTFIL DD:MYOUTPUT2,INCLUDE=(1,5,CH,EQ,'SCOTT',AND,16,5,CH,EQ,'TIGER') OUTFIL DD:MYOUTPUT3,INCLUDE=(1,5,CH,NE,'SCOTT',OR,16,5,CH,NE,'TIGER') OMIT DUPRECSCommand lines (UNIX):
MYINPUT1=/tmp/myappl/data1 \ MYINPUT2=/tmp/myappl/data1 \ MYINPUT3=/tmp/myappl/data1 \ MYOUTPUT1=/tmp/s1 \ MYOUTPUT2=/tmp/s2 \ MYOUTPUT3=/tmp/s3 \ hxsm -vv job12.xsm
Pas d'équivalent ligne de commande complète, à cause des formes DD:varname,INCLUDE=
Job 13 : "Tout en Un" : Fusion + Dédoublonnage + Skip Header + sortie sélective CSV
Fichier Paramètres job13.xsm :
# # Sample CSV demo # SORT VFIELDS=(9,2,C,A,8,30,C,A,10,5,N,A),FIELDSEP=COMMA ; ! ! ; ! +--- Field separator Comma (,) ; ! ; +-- sort keys #1: Field 9, max len 2, Char, Ascending ; +----- sort keys #2: Field 8, max len 30, Char, Ascending ; +----------- sort keys #3: Field 10, max len 5, Numeric, Ascending RECORD RECFM=V,LRECL=400 ; ! +--- max record length 400 ; no NewLine within 400 bytes will raise an error ; +-- Record Format : Variable SKIP_HEADERS 1 ; drop first line from every input file OMIT DUPLICATE RECORDS ; remove records with all fields duplicate INPFIL clients1.csv ; input file #1 INPFIL clients2.csv ; input file #2, will merge with input file #1 # All : OUTFIL DD:ALLCLIENTS # Only people from New-york state : OUTFIL DD:NEWYORKERS,INCLUDE=(9,2,CH,EQ,C'NY') # All but New-yorkers ! OUTFIL DD:OTHERS,EXCLUDE=(9,2,CH,EQ,C'NY')Command lines (UNIX) :
ALLCLIENTS=/myappl/out/clients1.csv \ NEWYORKERS=/myappl/out/clients1.NY.csv \ OTHERS=/myappl/out/tmp/clients1.not_in_NY.csv \ hxsm692_64 -vv job13.xsm
Pas d'équivalent ligne de commande complète, à cause du VFIELD et des différents DD:xx,INCLUDE=
 Il y a une démo de ce job ! Voir la démo
Il y a une démo de ce job ! Voir la démo
7. Tri destructif et non-destructif
XSM fonctionne en mode destructif par défaut : il ne garantit pas que l'ordre original des ensembles de lignes ou enregistrements ayant la(les) même(s) clé(s) de tri seront conservées.
Les algorithmes de tris propres à chaque utilitaire de tri produiront des résultats différents et indéterminés, ceci pour des raisons de performances.
XSM devient un tri non-destructif (ou tri "stable") avec l'option :
OPTION KEEP_ORDER=YES (dans un fichier paramètres)ou
--keep-order (option de ligne de commande)
Exemple : fichier en entrée :
01234 SMITH John
01738 SMITH Robin
02284 ALLEN David
04264 ALLEN Bob
Résultat par défaut (destructif), avec clé de tri = Nom :
La famille ALLEN puis la famille SMITH, le fait que les prénoms aient été désordonnés par rapport au fichier en entrée n'est pas important.
04264 ALLEN Bob
02284 ALLEN David
01234 SMITH John
01738 SMITH Robin
Résultat en mode Non-destructif (ou "stable") :
Les enregistrements, un fois triés sur la clé indiquée, conservent l'ordre qu'ils avaient dans le fichier en entrée.
02284 ALLEN David
04264 ALLEN Bob
01234 SMITH John
01738 SMITH Robin
Note: Forcer le mode non-destructif peut dégrader les performances car l'enregistrement entier est traité, pas uniquement la clé de tri.
Pour de meilleures performances, il est recommandé d'ajouter si besoin des clés de tri supplémentaires et d'éviter de forcer le mode non-destructif.
8. Conseils pour les performances
Consultez nos Relevés de Performance.
Le programme XSM est un tri multiphases : s'il ne peut pas trier l'ensemble des fichiers en entrée en mémoire vive en une seule passe, il écrit sur disques, puis interclasse, des portions toutes triées appelées 'monotonies', puis les fusionne dans le fichier en sortie.
Les performances sont liées :
- à la taille des fichiers à trier,
- au type des fichiers à trier (longueur Fixe ou Variable),
- à la quantité de mémoire vive disponible au moment de l'opération,
- à la qualité du Système d'Exploitation,
- à la quantité et la vitesse des disques physiques disponibles.
Sinon, XSM constitue des monotonies qu'il écrit dans des fichiers de travail, puis les interclasse dans d'autres fichiers de travail, et ce jusqu'à l'interclassement final dans le fichier de sortie.
Dans ce cas les performances sont essentiellement liées à la vitesse des unités de disques.
Longueur Fixe ou variable
Si de plus les clés de tri sont des champs de longueur variable (VFIELDS), les performances sont divisées par un facteur deux.
Les enregistrements de longueur fixe sont lus et écrits par blocs volumineux, d'où gain important d'entrées/sorties.
Si l'on utiliser des filtres 'INCLUDE/EXCLUDE/OMIT', les lectures sont unitaires, exactement comme pour le format variable.
Bien que l'on puisse allouer jusqu'à 512 Meg., on sait qu'au delà d'une certaine limite, le Système d'exploitation passera la quasi-totalité du temps à paginer.
A partir de la version 5, XSM calcule lui-même ses besoins en mémoire, en général :
Pour les très gros fichiers, ce calcul peut provoquer un forte pagination Vous pouvez donc dans ce cas utiliser le paramètre STORAGE pour limiter le phénomène.
Exemple : tri d'un fichier de 50 GB sur une machine à 128 MB.
Vous voulez réserver au moins 80MB pour votre Système d'exploitation :
STORAGE 48M
XSM passera plus de temps dans les opérations de fusion, mais vous échapperez au tristement célèbre phénomène de 'System Stress'.
Quelques remarques :
UNIX : on peut toujours donner une bonne priorité à un travail (commande 'nice'), mais elle n'influe guère.
Windows : amusez-vous avec la souris pendant un tri volumineux et le temps de tri est multiplié par 10 !!!
Les bonnes pratiques :
- Commencer par mettre au point vos jobs XSM sur un système peu chargé (CPU, RAM, I/O)
- puis testez ces traitements sur la machine cible (activité de production).
- et observez les résultats : si les temps de traitements XSM sont dégradés, c'est le moment d'étudier le système cible et d'y rechercher les processus surconsommateurs de ressources CPU, Mem, disk I/O.
Gardez à l'esprit que sur les machines actuelles, le goulot d'étranglement reste l'entrée/sortie sur disque physique : CPU et mémoire sont très rapides par rapport aux unités mécaniques tels que les disques.
Autant que possible, paramétrez XSM pour utiliser différents disques physiques, cela sera radical.
Si possible, mettre les fichiers d'entrée et de sortie (ils peuvent ne faire qu'un) sur une unité, et les fichiers de manoeuvre sur une autre, comme expliqué à la section SORTWORKS.
Assurez vous cependant que vous avez suffisamment de place sur chaque unité : au moins la taille du fichier en sortie sur la 1ere unité, et un au moins quart de cette taille sur l'autre.
Sur un vrai Système multi-tâches (UNIX, OS/2, Win NT), il est possible que d'autres programmes (et le Système lui-même) utilisent telle ou telle unité : choisissez les disques les moins 'fréquentés'.
Et pour terminer, ne confondons pas :
et
'Deux unités physiques C: et D:'
(même remarque pour les Filesystems UNIX).
9. Utilisation de la librairie de programmation XSM (User Exit)
Il y a deux façons d'utiliser XSM comme tri interne dans un programme, via la technique dite "User Exit" :
- Vous fournissez vos propres fonctions d'entrée/sortie sous forme de bibliothèque (en anglais Library) dynamique décrites dans le fichier paramètre comme indiqué ci-dessous, et XSM chargera cette bibliothèque à son initialisation, puis fera appel à ces fonctions I/O à la place de se charger lui-même des entrées/sorties
- ou, vous écrivez votre propre programme, qui appelle une fonction XSM avec un paramètre et des pointeurs de fonctions vers vos propres fonctions d'entrées/sorties, puis vous compilez et link-éditez votre programme avec la bibliothèque XSM.
Fourniture de votre propre bibliothèque dynamique
- Codez, compilez, link-editez votre module avec vos fonctions lecture/écriture des fichiers INPUT/OUTPUT, enregistrement par enregistrement, ou ligne par ligne :
int your_read_routine(char * hxsm_buffer, int hxsm_buffer_max_length)Appel :
itératif, jusqu'à retour d'une valeur négative Retourne :
longueur de l'enregistrement si OK,
ou -1 si End Of FileF,
ou -2 si erreur
.int your_write_routine(char * hxsm_buffer, int hxsm_buffer_actual_length)Appel :
unitaire, pour chaque enregistrement prêt à être écrit,
plus un appel APRES écriture d'un dernier enregistrement avecxsm_buffer = NULL, andxsm_buffer_actual_length = -1;Retourne :
0 ou valeur positive si OK,
valeur négative si erreur.
- Dans le Fichier Paramètres, remplacer les paramètres INPFIL et/ou OUTFIL par les paramètres :
INPXIT LIBRARY=libname1,ENTRY=function1 OUTXIT LIBRARY=libname2,ENTRY=function2où libname1, libname2 sont les noms des bibliothèques contenant les fonctions (peut être la même bibliothèque)
et function1, function2 sont les noms de fonctions respectifs pour l'entrée (INPXIT) et la sortie (OUTXIT)
- Codez, compilez, link-editez votre module avec vos fonctions lecture/écriture des fichiers INPUT/OUTPUT, enregistrement par enregistrement, ou ligne par ligne :
Utilisation de la bibliothèque XSM
XSM fourni une bibliothèque de programmation avec une routine publique qui peut être appelée par votre programme, écrit dans un langage compilé supportant le link-edit, tel que C, C++, C#, VB, ... :Fonction hxsm_begin
Synopsis :int hxsm_begin(parms_string, my_read_function, my_write_function)où :
parm_string est soit le nom d'un fichier paramètres, soit un chaîne de caractères contenant l'équivalent d'un fichier paramètre, ou les paramètres de la ligne de commande hxsm.
my_read_function est un pointeur sur votre propre fonction d'entrée, de synopsis suivante :
int myread(char * buffer, int max_length)et qui, à l'appel, doit fournir soit le prochain enregistrement à trier et sa longueur, soit max_length = -1 sur fin de fichier (EOF).
my_write_function est un pointeur sur votre propre fonction de sortie, de synopsis suivante :
int mywrite(char * buffer, int rec_length)et qui, à l'appel, doit recevoir soit le prochain enregistrement et sa longueur, soit un buffer NULL et une longueur -1 (EOF).
Retourne : 0 si Ok, ou négatif si erreur.
Sous Windows, les bibliothèques dynamique se nomment 'SOMELIB.DLL'.
Sous UNIX/Linux, les bibliothèques se nomment 'libsomething.a' pour les statiques et 'libsomething.so' pour les dynamiques.
Exemple :
Le module suivant est compilé, puis link-edité pour produire 'libmysrt.a' (AIX), ou 'libmysrt.so' (LINUX), ou 'MYSRT.DLL' (Windows):
#include <stdio.h>
int myread(char * xsm_buf, int xsm_maxl) {
/* this routine reads on stdin, and arrange the lines to be sorted */
/* the lines beginning with a '*' are to be dropped */
char mybuf[134];
do if (gets(mybuf) == NULL) return EOF;
while (mybuf[0] == '*');
/* set up the record to be sorted, return its length */
return sprintf(xsm_buf, "%-5.5s%-20.20s%s", mybuf+20, mybuf,mybuf+25);
}
int mywrite(char * xsm_buf, int xsm_len) {
/* this routine arrange the sorted lines and write them onto stdout */
if (xsm_len > 0)
printf("-20.20s%-5.5s%s\n", mybuf+5, mybuf, mybuf+25);
return 0;
}
Then the library is moved somewhere in the 'PATH' (Windows), or in the 'LD_LIBRARY_PATH' (UNIX) directories list;
Finally, the hxsm module is run with the following fichier paramètres:
SORT FIELDS=(25,5,B,D,1,20,B,A) RECORD RECFM=V,LRECL=132 INPXIT LIBRARY=mysrt,ENTRY=myread OUTXIT LIBRARY=mysrt,ENTRY=mywrite
Exemple :
Le programme C suivant demande, en itération, un nom et un montant, jusqu'à ce que l'utilisateur entre le signal EOF (^Z ou ^D), puis affiche les lignes saisies triées par montant descendant, puis affiche le total.
Il est compilé, puis link-edité avec la bibliothèque hxsm.
#include <stdio.h>
double atof(), total = 0.0;
static int myread(char * buf, int maxlen) {
char work_area_1[133], work_area_2[133];
double amount;
/* prompt for a name and an amount, returns -1 if EOF */
printf("Name :" ); if (gets(work_area_1) == NULL) return -1;
printf("Amount :" ); if (gets(work_area_2) == NULL) return -1;
amount = atof(work_area_2);
return sprintf(buf, "%9.2f %-30.30s", amount, work_area_1);
}
static int mywrite(char * buf, int len) {
if (len > 0)
printf("%-30.30s %-12.12s\n", buf + 13, buf);
return len; /* will be ignored by hxsm */
}
main(int argc, char **argv) {
int rc = hxsm_begin("MYPRM.XSM", myread, mywrite);
if (rc == 0)
printf("%-30.30s %9.2f\n", "*** TOTAL ***", total);
else
printf("Failed, rc %d\n", rc);
return rc;
}
Le programme utilise le fichier paramètre MYPRM.XSM suivant :
SORT FIELDS=(1,12,B,D) RECORD RECFM=V,LRECL=132On peut également coder les paramètres de lignes de commandes au lieu du nom de fichier paramètre :
int rc = hxsm_begin("-k1,12,d", myread, mywrite);
et lancer le programme sans utiliser de fichier paramètres.
