 English
English
Le temps, c'est de l'argent : Accélérez vos traitements !
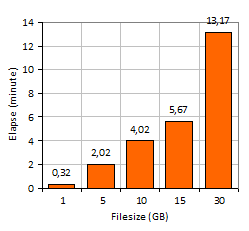
XSM trie 1 Gigaoctet en
4020 secondes, 10 Giga en54 minutes, sur une machine à moins de 500 Euros !
Qui dit mieux ?
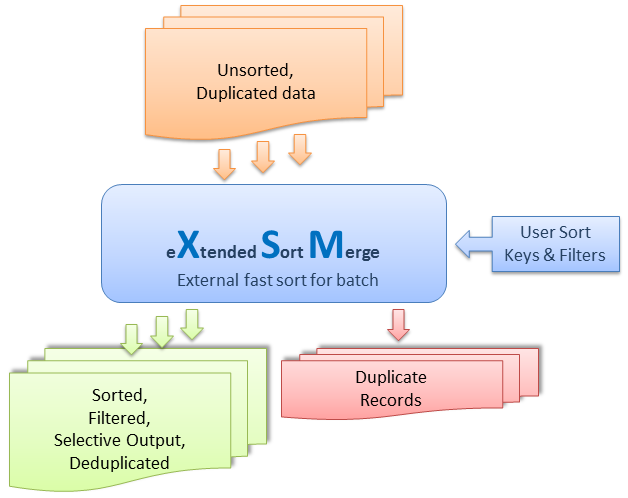
Mais pourquoi utiliser un tri externe ... ??
Témoignages
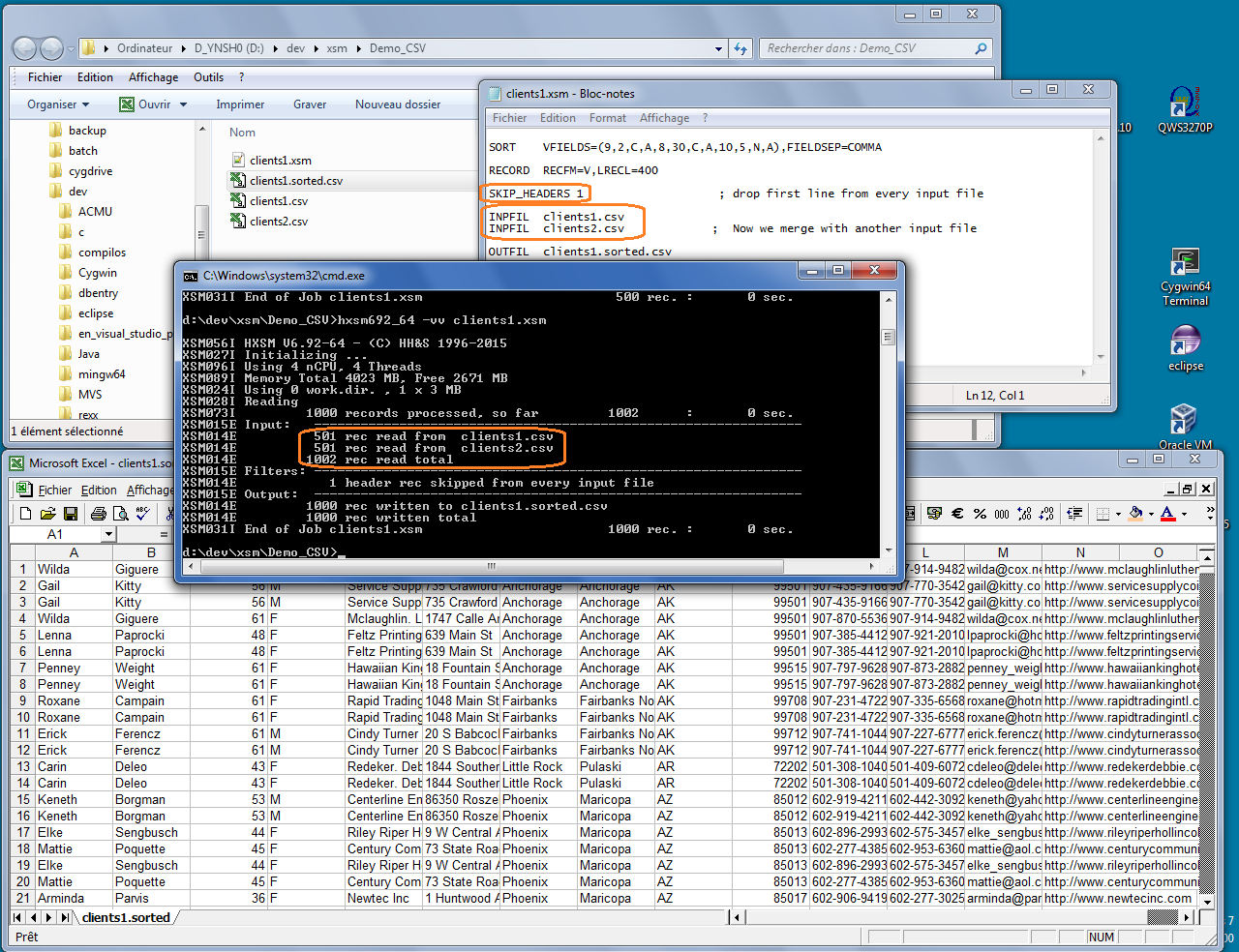
Dernièrement, nous avons remplacé une commande de tri UNIX classique par hxsm pour trier une colonne d'un fichier de 150 Mo :
Soit plus de 90 % de gain de performance par rapport au tri classique...
Démo
Découvrez en quelques slides comment réaliser simplement un Tri / Fusion / Dédoublonnage / Eclatement sélectif de fichiers textes type Csv
Vos challenges :
- Trier, fusionner, ventiller, filtrer, dédoublonner rapidement vos gros fichiers de données atteignant des centaines de Gigaoctets sur des machines économiques
- Traiter quotidiennement et rapidement de gros volumes
- Accroître vos capacités de production en réduisant de 20 heures à 4 heures des temps de traitement
- Accélérer les échanges de données ETL/EDI de votre DataWareHouse
- Optimiser vos coûts Logiciels en quittant un logiciel concurrent beaucoup plus cher
La solution :
- XSM, déjà adopté par plus de 60 clients dans 12 pays
- XSM possède des performances remarquables grâce à sa technologie propriétaire multi-threading tirant partie au mieux des architectures multi-processeurs actuelles, tant sur des machines haut de gammes IBM, SUN, HP, que de simples PC à processeurs multi-cores.
- XSM a des fonctionnalités puissantes répondant aux besoins classiques de Tri /
Fusion / Eclatement / Filtrage nécessaires aux traitements Métiers du DataWareHousing et DataMining.
Avec l'évolution des technologies de l'Information (capacités de stockage, puissance CPU), les volumes de données ont explosés en 10 ans et l'on ne peut plus simplement s'appuyer sur la puissance CPU : les performances du logiciel sont essentielles !
Mais pourquoi utiliser un tri externe ?
1. Tri externe pour accélérer un chargement de base de données
Supposons que vous deviez recharger toutes les nuits des fichiers de volumétrie importante dans votre base de données préférée Oracle, DB2, MySQL, SQL-Server, Informix, Sybase, ...Dans cet exemple, nous prenons MySQL, car il est assez rapide dans le chargement de données.
Supposons que vous ayez une table fortement indexée, et que vous deviez chaque nuit détruire le contenu de la table et recharger dans cette table le contenu de fichiers,
- si vos données externes (fichiers) ne sont pas triées, c'est le serveur de base de données qui fera le travail
- si vos données externes sont préalablement triées, le serveur de base de données n'aura qu'à les charger, sans effort pour construire ses indexes.
Regardons le résultat sur ce benchmark :
- Chargement d'un fichier texte ASCII de 100MB, soit 1023009 enregistrements
- Enregistrements de longueur variable, séparés par Tabulation, 5 colonnes : 2 entiers, 2 chaînes de caractères
- Moteur MySQL Server 4.0.10-gamma sous Linux 2.4.18 sur Pentium II/550Mhz 512MB RAM (peut importe, le phénomène est identique sur tout SGBDR)
- La figure montre la durée totale de chargement en secondes :
 Chargement DB de données non triées :
Chargement DB de données non triées :
- data loading : 10200 secs
- total : 10200 secs = 2 heures 50 minutes 28 secs.
 Chargement DB de données pré-triées :
Chargement DB de données pré-triées :
- pré-tri : 315 secs. (avec XSM V5.08)
- data loading : 213 secs
- total : 528 secs. = 8 minutes 48 secs. pratiquement 20 fois plus rapide !
Vous comprenez maintenant l'intérêt du tri externe : il accélère le chargement de données volumineuses.
Ne confiez pas cette tâche à votre moteur SGBDR intégré "qui sait tout faire!" : ce n'est pas son travail !
2. Fusion / Eclatement / Filtrage / Copie sélective / Identification et suppression des doublons
Vous souhaitez fusionner / éclater / filtrer / copier des données selon des critères donnés.Prenons un exemple simple : Vous recevez quotidiennement le rapport des ventes composé de 50 fichiers et vous souhaitez éclater ces données par départements, en créant un fichier par département.
Deux solutions :
- Utiliser votre SGBD : la plupart des informaticiens vont penser à cette option, mais ce n'est pas la bonne !
- Drop / Create de la table : 30 secondes
- Charger les 50 fichiers dans une table : 1 heure
- Passer un traitement SQL de dédoublonnage : 1 heure
- Passer 100 traitements UNLOAD, un par département : 2 heures
Durée totale (estimée) : 4 heures
- Utiliser XSM en tri/fusion batch : La bonne solution !
- En une seule et même opération, XSM effectue fusion / tri / dédoublonnage / éclatement sélectif
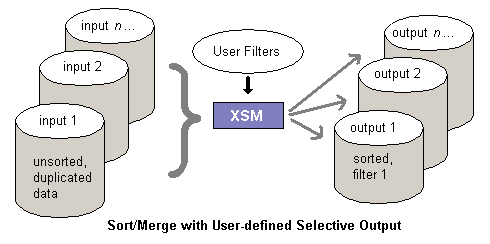
Durée totale (estimée) : 5 minutes
